
Does Generative AI truly help in Software Engineering? AI support using LLM models

Author
Gustaw Szwed – Senior Developer
Created
September 16th, 2025
This paper is in the form of a laid-back column, mostly personal opinions of mine. But first of all, I recommend reading our two previous articles – one from Krzysztof Dukszta-Kwiatkowski: Frontend developer perspective onusing AI code assistants and LLMs and one in the form of an interview with Łukasz Ciechanowski by Rafał Polański: AI and DevOps: Tools, Challenges, and the Road Ahead – Expert Insights. Now it’s time for another case study – a backend development perspective.
My environment and a bit about me
I’ve been working as a software engineer in multiple languages (not to mention dozens of frameworks, either). Now I stick with Reactive Java and Spring – wouldn’t call it my first choice, but so far, it’s the least painful and allows me and my team to deliver high-quality projects on time. And then – ChatGPT appeared with a big bang. As mentioned in the linked articles, it opened a new world for software engineers. This Pandora’s box also created many doubts in terms of Intellectual Property rights, like stealing artwork from artists through generative image AI.
How it all started
At the beginning, software engineers relied mostly on AI chatbots – where they provided some questions, code snippets and so on. Nowadays, those are often integrated in our IDEs – I use IntelliJ IDEA Ultimate with JetBrains AI Assistant Plug-in as my daily tools. I also tried other plugins like those provided straight from OpenAI – I guess everyone recognises their ChatGPT.
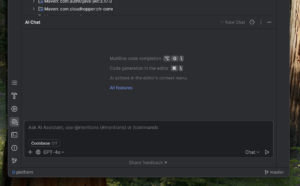
As you may see, it’s an integrated ChatBot. You can also change the LLM model to a different one – not only those from OpenAI (like GPT-4o), but also from Google (Gemini) or Antropic (Claude). It also allows you to generate code straight in your editor – but with varying results:
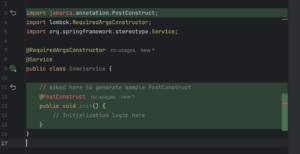
As you may see, it generated a sample straight from Jakarta EE (previously known as simply Java EE) instead of Spring’s PostConstruct, which comes straight from javax. On the contrary, when I have doubts while writing sophisticated Reactive chains, I can always ask an AI assistant for advice – and not only do I get some hints, but also it explains to me some steps and changes they made:
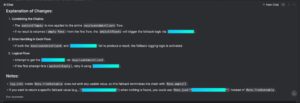
It allows engineers to refactor Reactive code with proper fallbacks (which is not that intuitive for starters), configure loggers (not only logback, but also allow to include Logbook), or when they want to generate some Java records based on a sample JSON (or vice versa), it does its job really well. The same thing happens with Jackson or Swagger annotations, so it really accelerates the software development. And it also has a great knowledge about many external APIs – KeyCloak user, role and group management? No problem. Oauth2 support, Kafka brokers, everything needed daily – it shows its potential. But with everything, there’s a pinch of tar – when I asked an AI assistant for some simple CSV file transformation when providing a table, it couldn’t understand how to manage some strings and just made up the results. Also, if a developer doesn’t know what they’re doing and relies only on AI assistants, they will quickly find out they are in a dark alley with AI-provided solutions that totally don’t make any sense.
Damage is done
Around all the controversies with not-so-legal fetched materials for learning LLM (large language models) or image generation models (like Stable Diffusion), it also allowed engineers like me to greatly increase productivity – but with some cost. LLM models are based on our existing content – repositories, Stack Overflow questions and replies, news, documentation and articles. If you want it or not, you’re part of it now, even if you opt-out (you can truly opt-out?). Obviously, you don’t have to use AI assistants too, but as you may see above, it accelerates coding, so there’s a chance you will stay behind. But even as a part of this trend, there’s still one big challenge ahead of us – degradation of input material for LLM models. Stack Overflow and other portals have seen dramatically decreased traffic, and that’s a really bad situation – no one can rate replies, review them, give some feedback or promote a given advisor to a higher rank.
We lost control
Those are bold words, but you will not find better words for that – we don’t control input nor output of LLM models, no one can guarantee that results aren’t made up, don’t come from unreliable (or what’s worse – shady) sources, won’t spoil someone’s Intellectual Property, etc.
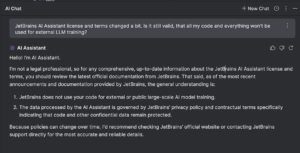
But can you truly trust it? Of course, we use IntelliJ IDEA, WebStorm, Xcode and other IDEs, but it’s local and we can (at least theoretically) check the traffic that comes in and out from our Mac or PC. Now we don’t have any guarantees that our queries don’t flow around the globe.
Corporate policy
Some companies are afraid of that; therefore, they simply don’t allow engineers to use any AI assistant, which may be harmful for them. Their colleagues from other companies can now improve their work, for instance, help the DevOps team to provide Ingress rules (because they can learn it with an AI assistant in no time), and understand their code better. Every smart business on the market provides its own servers with LLM models. It’s not a perfect solution, it’s quite often not up-to-date with the newest versions of frameworks or libraries, and doesn’t allow (most often) to pick other LLM models like the JetBrains AI plug-in does. Maintaining those servers doesn’t come cheap, not only because of DevOps work, but also at a resource level – it requires a lot of disk space and computing power. But at least they’re in control, and that’s a trade-off they prefer to keep. There is also possibility to run LLM on local machines (vide Ollama, LM Studio or HuggingFace), but those require powerful work machines and for many engineers who just use their company laptop it may be too much (in terms of battery life and thermal considerations) – for more information I suggest to read article from Krzysztof Dukszta-Kwiatkowski mentioned at the beginning of this column.
They took our jobs!!!
That’s the biggest fear of engineers, which I totally don’t agree with. With or without the AI trend, the level of engineering skills has degraded in the past. As a technical recruiter, I noticed most engineers just came “to work”, whereas software engineering is way more. And they burn out quickly, don’t learn new things and follow new trends and technologies on the market, including new frameworks. I would rather work with two great engineers than with 10 average ones, because the knowledge sharing is really time-consuming and doesn’t move the project forward. In the past years, companies have been over-recruiting, so now only good engineers can find a great project to be part of, and for them, the AI assistant is a great tool to push those projects at a higher pace.
Conclusions
In summary, while AI assistants like ChatGPT have undeniably changed the way we approach backend development – speeding things up, filling knowledge gaps, and even acting like a second pair of eyes – they’re still just tools. Powerful, yes, but imperfect. As engineers, we have to stay sharp, question the output, and keep learning the fundamentals. Otherwise, we risk becoming over-reliant on something we don’t fully understand or control. The landscape is shifting fast, and it’s up to us to adapt thoughtfully, not blindly follow the trend.